
Инжиниринг Данных
Делюсь новостями из мира аналитики и карьерными советами. 15 лет в Аналитике и Инжиниринге Данных, 10 лет в MAANG 🛠️ dataengineer.ru | 🏄♂️ Surfalytics.com №5017813306 Реклама: https://almond-rule-130.notion.site/1199f595f76a8030ba1be1e607c9a8ce
![[object Module]-logo](/_next/static/media/telegram.70d3df3f.png)
Что бы я сделал по-другому
Самое очевидное — это банальный prompt engineering. Вы видели мой наивный запрос. Что попросил, то и получил. Причём к самой инфраструктуре почти нет вопросов. А вот там, где уже надо включать голову, оказалось сложнее. Если бы я взял свой prompt и с помощью LLM сделал чёткий и конкретный план, я бы получил совсем другой результат.
Обязательно надо прописывать критерии успеха и пути тестирования.
К сожалению, я не сделал YOLO режим, и нужно было раз 100 нажать accept.
В каком-то смысле агенты работают со своей Spec, планируют и выполняют задачи последовательно, как если бы я использовал OpenSpec и запускал задачи сам.
В реальных задачах я бы ещё не доверил end-to-end агентам, но у меня просто нет такой необходимости и таких задач. Я всё ещё сам хочу контролировать архитектуру, инструменты. Но прогресс налицо.
Цена вопроса
Так как я гонял Opus 4.6 ещё и на рабочие задачки, то сложно сказать конкретно стоимость этого упражнения. Я использую Anthropic API, и там нет привычных лимитов. За вечер я сжёг $40 и потратил 55 млн токенов. Хотя если посмотреть Claude stat, то видно, что больше половины токенов — это cache-токены, которые дешевле.
Цена Azure-ресурсов — $2 в день для моего стенда.
Что можно ещё сделать
Таким образом можно создать готовые решения на Azure, AWS, GCP в целях обучения и pet-проектов. Можно тестировать batch/streaming и моделирование хранилища данных.
Следующее упражнение я хочу сделать на Open Source, чтобы всё деплоилось на локальном Docker или Kubernetes, но уже скормить хороший spec на вход.
PS Я реально получил удовольствие от процесса, и в какой-то степени сессии с Claude Code заменили потребность в doom scrolling и социальных сетях.
PPS Если вы недавно стали работать инженером/аналитиком (не только DE, любым), то вы в опасности.
Нет, не потому, что вас AI заменит, а потому, что теперь можно, не напрягаясь, очень легко получить хороший результат, при этом совершенно не понимая, что происходит.
Вот мне AI сохранил пароль в pipelines и другие ляпы, а для новичка это непонятно.
Вы можете работать месяцами, и AI будет делать за вас работу, но вы не будете развиваться и не будете понимать основ, таким образом годы опыта не будут считаться реальным опытом.
Так что поаккуратнее там с AI.
Почему я такой эффективный с AI? Это не только потому, что AI такой крутой, а потому, что у меня 15 лет опыта, и первые лет 12-13 я всё делал руками и гуглил каждую ошибку.
Поэтому сейчас AI мне помогает делать быстрее то, что я знаю и умею. И это ключевое отличие на данном этапе. Возможно, в будущем и этот эффект пропадёт, и мои знания тоже обесценятся, а пока можно кайфовать - золотое время матерых инженеров📈
Самое очевидное — это банальный prompt engineering. Вы видели мой наивный запрос. Что попросил, то и получил. Причём к самой инфраструктуре почти нет вопросов. А вот там, где уже надо включать голову, оказалось сложнее. Если бы я взял свой prompt и с помощью LLM сделал чёткий и конкретный план, я бы получил совсем другой результат.
Обязательно надо прописывать критерии успеха и пути тестирования.
К сожалению, я не сделал YOLO режим, и нужно было раз 100 нажать accept.
В каком-то смысле агенты работают со своей Spec, планируют и выполняют задачи последовательно, как если бы я использовал OpenSpec и запускал задачи сам.
В реальных задачах я бы ещё не доверил end-to-end агентам, но у меня просто нет такой необходимости и таких задач. Я всё ещё сам хочу контролировать архитектуру, инструменты. Но прогресс налицо.
Цена вопроса
Так как я гонял Opus 4.6 ещё и на рабочие задачки, то сложно сказать конкретно стоимость этого упражнения. Я использую Anthropic API, и там нет привычных лимитов. За вечер я сжёг $40 и потратил 55 млн токенов. Хотя если посмотреть Claude stat, то видно, что больше половины токенов — это cache-токены, которые дешевле.
Цена Azure-ресурсов — $2 в день для моего стенда.
Что можно ещё сделать
Таким образом можно создать готовые решения на Azure, AWS, GCP в целях обучения и pet-проектов. Можно тестировать batch/streaming и моделирование хранилища данных.
Следующее упражнение я хочу сделать на Open Source, чтобы всё деплоилось на локальном Docker или Kubernetes, но уже скормить хороший spec на вход.
PS Я реально получил удовольствие от процесса, и в какой-то степени сессии с Claude Code заменили потребность в doom scrolling и социальных сетях.
PPS Если вы недавно стали работать инженером/аналитиком (не только DE, любым), то вы в опасности.
Нет, не потому, что вас AI заменит, а потому, что теперь можно, не напрягаясь, очень легко получить хороший результат, при этом совершенно не понимая, что происходит.
Вот мне AI сохранил пароль в pipelines и другие ляпы, а для новичка это непонятно.
Вы можете работать месяцами, и AI будет делать за вас работу, но вы не будете развиваться и не будете понимать основ, таким образом годы опыта не будут считаться реальным опытом.
Так что поаккуратнее там с AI.
Почему я такой эффективный с AI? Это не только потому, что AI такой крутой, а потому, что у меня 15 лет опыта, и первые лет 12-13 я всё делал руками и гуглил каждую ошибку.
Поэтому сейчас AI мне помогает делать быстрее то, что я знаю и умею. И это ключевое отличие на данном этапе. Возможно, в будущем и этот эффект пропадёт, и мои знания тоже обесценятся, а пока можно кайфовать - золотое время матерых инженеров📈
Telegram
Поделюсь опытом создания Azure инфраструктуры для пет проекта. Сейчас у нас закончился проект Surfalytics, где я 2 часа рассказывал про Azure reference architectures и пример создания решения с и без агентов. Но запись не сработала😿
Вот, что я заказал у agent teams:
Отлично, теперь я использую команду для построения своего рода Azure Data Warehouse используя:
Azure SQL Server как мою source database
Azure CosmosDB как мою source NoSQL database
Azure Postgres как мой data warehouse
Azure Data Factory для загрузки данных из sources в Postgres (destination)
Azure DevOps Repos для кода, мы можем подключить Azure DevOps для Azure Data Factory, а также для любых видов transformations. У меня есть account https://dev.azure.com/surfalytics/
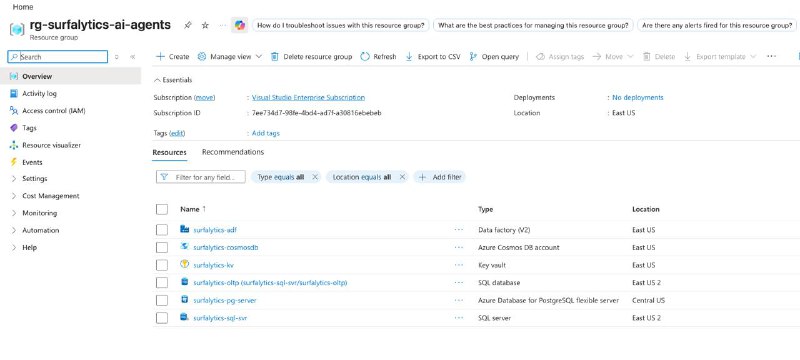
вы можете начать с новой resource group в Azure rg-surfalytics-ai-agents и создать все resources. Убедитесь, что они находятся в одном Region.
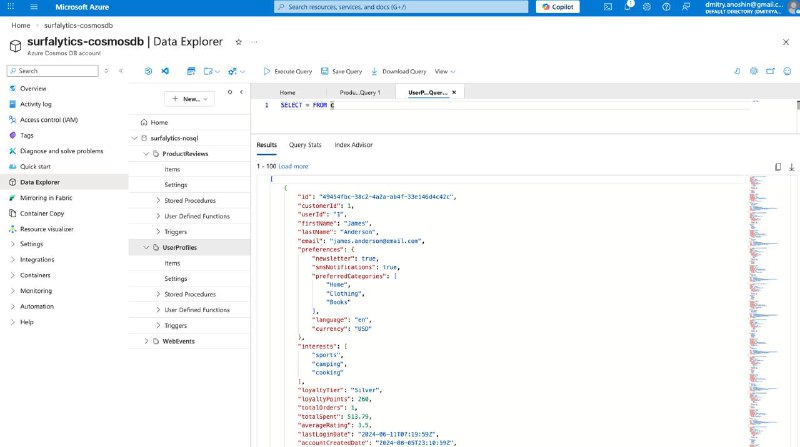
вы можете сгенерировать sample data в SQL Server как OLTP для SQL Server и Documents для CosmosDB
мы выполнили az (Azure CLI) и он залогинен в Azure Subscription
Вы можете использовать team of agents для разделения работы и убедиться, что у нас есть working solution в Azure.
Что сделал Claude Code Team Agents:
| Task | Status | Agent |
|-----------------------|-------------------|----------------|
| #1 Infrastructure | Completed | infra-agent |
| #2 SQL Server data | In progress | data-agent |
| #3 CosmosDB documents | Starting now | infra-agent |
| #4 Warehouse schema | Completed | infra-agent |
| #5 ADF Pipelines | Waiting on #2, #3 | pipeline-agent |
| #6 DevOps + CI/CD | Waiting on #5 | pipeline-agent |
То есть создал 6 задач и несколько агентов, причем некоторые задачи могут выполняться параллельно.
Что я получил на выходе и оценка от 1 до 5.
• Azure Resource Group в которой создались все ресурсы - 5
• Azure CosmosDB с одной БД и 3мя контейнерами и JSON документами как sample - 5
• Azure SQL Server с новой базой данных и sample таблица - 5
• Azure Postgres (data warehouse) пустой - 5
• Azure Data Factory сам workspace - 5
• Использование Azure CLI для всех задач - 5 (и не нужен MCP)
• Сохранить все в Azure DevOps Repo - 4 (даже не смотря на то, что это то как я хотел, но я не объяснил нормально)
Теперь, где оказались проблемы
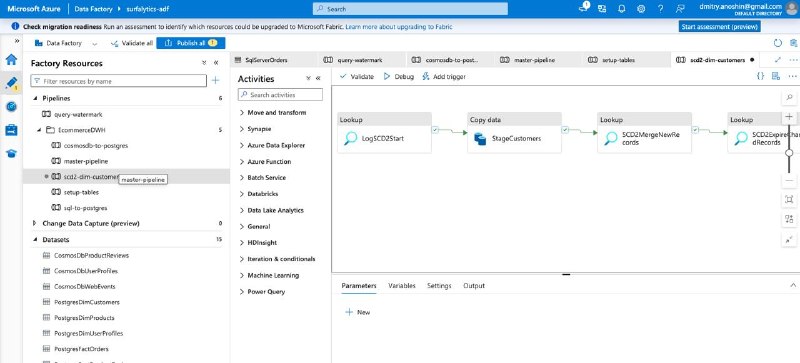
• Когда все закончилось, я пошел в ADF и нашел pipelines, но они не работали, то есть где-то, что-то потерялось. Я попросил агентов починить, и они все починили. И тут я понял, что я не написал заранее про тестирование всего, что мы сделали.
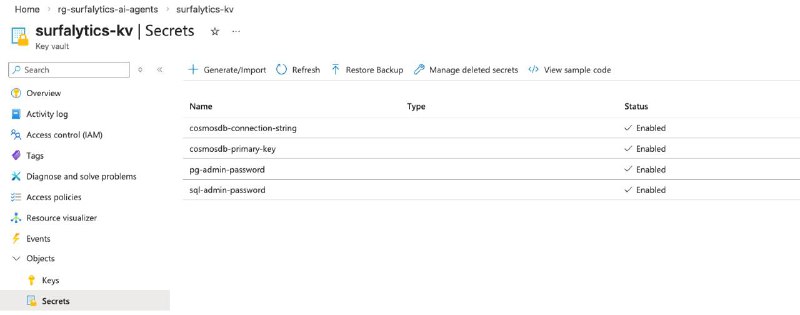
• Все пароли оказались прям в коде pipelines и я попросил использовать Azure Key Vault. Агент все сохранил в Azure Key Vault, но не обновил ничего внутри ADF. Опять же мой косяк, я не просил об этом.
• Сами data pipelines были странные. В CosmosDB у меня было 3 таблицы, в Azure SQL у меня было 4 таблицы. И я хотел что-то вроде dimensional model. По факту он создал 3 pipelines с COPY activity. Тут был прям худший результат. Но и мой запрос был очень поверхностный.
Дальше я попросил агентов добавить Watermark таблицу для инкрементальной загрузки и таблицу для логов запуска pipelines и поставить все на расписание.
• Агенты добавил новый adf pipelines и добавил в каждый возможность logging (но я бы так не сделал бы)
• Для SCD Агнеты сделали блоки с SQL командами INSERT/UPDATE, хотя INSERT блок назвали MERGE.
Поэтому за часть Dimensional Modelling я поставлю 1, даже после моих подсказок он всё равно не выполнил то, что я просил.
Вот, что я заказал у agent teams:
Отлично, теперь я использую команду для построения своего рода Azure Data Warehouse используя:
Azure SQL Server как мою source database
Azure CosmosDB как мою source NoSQL database
Azure Postgres как мой data warehouse
Azure Data Factory для загрузки данных из sources в Postgres (destination)
Azure DevOps Repos для кода, мы можем подключить Azure DevOps для Azure Data Factory, а также для любых видов transformations. У меня есть account https://dev.azure.com/surfalytics/
вы можете начать с новой resource group в Azure rg-surfalytics-ai-agents и создать все resources. Убедитесь, что они находятся в одном Region.
вы можете сгенерировать sample data в SQL Server как OLTP для SQL Server и Documents для CosmosDB
мы выполнили az (Azure CLI) и он залогинен в Azure Subscription
Вы можете использовать team of agents для разделения работы и убедиться, что у нас есть working solution в Azure.
Что сделал Claude Code Team Agents:
| Task | Status | Agent |
|-----------------------|-------------------|----------------|
| #1 Infrastructure | Completed | infra-agent |
| #2 SQL Server data | In progress | data-agent |
| #3 CosmosDB documents | Starting now | infra-agent |
| #4 Warehouse schema | Completed | infra-agent |
| #5 ADF Pipelines | Waiting on #2, #3 | pipeline-agent |
| #6 DevOps + CI/CD | Waiting on #5 | pipeline-agent |
То есть создал 6 задач и несколько агентов, причем некоторые задачи могут выполняться параллельно.
Что я получил на выходе и оценка от 1 до 5.
• Azure Resource Group в которой создались все ресурсы - 5
• Azure CosmosDB с одной БД и 3мя контейнерами и JSON документами как sample - 5
• Azure SQL Server с новой базой данных и sample таблица - 5
• Azure Postgres (data warehouse) пустой - 5
• Azure Data Factory сам workspace - 5
• Использование Azure CLI для всех задач - 5 (и не нужен MCP)
• Сохранить все в Azure DevOps Repo - 4 (даже не смотря на то, что это то как я хотел, но я не объяснил нормально)
Теперь, где оказались проблемы
• Когда все закончилось, я пошел в ADF и нашел pipelines, но они не работали, то есть где-то, что-то потерялось. Я попросил агентов починить, и они все починили. И тут я понял, что я не написал заранее про тестирование всего, что мы сделали.
• Все пароли оказались прям в коде pipelines и я попросил использовать Azure Key Vault. Агент все сохранил в Azure Key Vault, но не обновил ничего внутри ADF. Опять же мой косяк, я не просил об этом.
• Сами data pipelines были странные. В CosmosDB у меня было 3 таблицы, в Azure SQL у меня было 4 таблицы. И я хотел что-то вроде dimensional model. По факту он создал 3 pipelines с COPY activity. Тут был прям худший результат. Но и мой запрос был очень поверхностный.
Дальше я попросил агентов добавить Watermark таблицу для инкрементальной загрузки и таблицу для логов запуска pipelines и поставить все на расписание.
• Агенты добавил новый adf pipelines и добавил в каждый возможность logging (но я бы так не сделал бы)
• Для SCD Агнеты сделали блоки с SQL командами INSERT/UPDATE, хотя INSERT блок назвали MERGE.
Поэтому за часть Dimensional Modelling я поставлю 1, даже после моих подсказок он всё равно не выполнил то, что я просил.
+2
Telegram
Ох уж эти агенты, невозможно оторваться! Сколько всего можно сделать, когда знаешь, как вежливо попросить AI сделать это за тебя:
• новые Airflow DAGs
• добавить новый источник данных Walmart API и встроить его в dbt модели в bronze/silver/gold, а также проверить, что ничего не сломалось
• создать новый проект для Surfalytics, чтобы выгружать всю историю в JSON для автогенерации Weekly Emails и создания RAG на основе накопленных знаний
• создать с нуля AWS хранилище данных на Redshift через AWS CloudFormation и подключить к нему dbt, чтобы через dbt-external-tables читать сотню таблиц, используя Redshift Spectrum — вообще целый проект миграции с on-premise на AWS под ключ можно сделать с AI
• создать упражнения для последней главы нашей новой книги Azure Databricks Data Engineering, причём глава о ML и GenAI
• создать Azure DevOps pipelines для Databricks и написать ко всему этому документацию
• прочитать проектные документы и написать развёрнутые ответы
• добавить интеграцию Plaid API в Airflow и dbt модели
• накатать документацию по Subscription (это единственный прощальный проект, про который я писал, но решил сдаться)
• изучить новую фичу Claude Code Agent Teams и запустить тест по созданию с нуля Azure Data Warehouse с Azure SQL Server, Azure CosmosDB, Azure Postgres, Azure Data Factory, Azure DevOps repos и pipelines. Я дал доступ к своему Azure аккаунту и поставил задачу создать всё самостоятельно — ещё создаёт. То есть если подождать немного, то уже не нужны всякие сложные GasTown, Multi Claude и т.п. У Cursor тоже есть Parallel Agents. Но у меня пока нет таких задач, где нужно вместе так рабоать, лучше просто режим YOLO и погнали 😡
Это что пришло в голову с ходу.
Очевидно одно: с такими возможностями можно реализовать любую идею очень быстро. Не знаю как у вас, но у меня 80-90% работы идёт через AI. Со вчерашнего дня использую уже Opus 4.6. Конечно, где-то бывают затыки, но вместе с AI всё решаемо. Для всех Surfalytics members AI IDE — must have. Без AI, я бы тоже самое делал бы 5 недель.
• новые Airflow DAGs
• добавить новый источник данных Walmart API и встроить его в dbt модели в bronze/silver/gold, а также проверить, что ничего не сломалось
• создать новый проект для Surfalytics, чтобы выгружать всю историю в JSON для автогенерации Weekly Emails и создания RAG на основе накопленных знаний
• создать с нуля AWS хранилище данных на Redshift через AWS CloudFormation и подключить к нему dbt, чтобы через dbt-external-tables читать сотню таблиц, используя Redshift Spectrum — вообще целый проект миграции с on-premise на AWS под ключ можно сделать с AI
• создать упражнения для последней главы нашей новой книги Azure Databricks Data Engineering, причём глава о ML и GenAI
• создать Azure DevOps pipelines для Databricks и написать ко всему этому документацию
• прочитать проектные документы и написать развёрнутые ответы
• добавить интеграцию Plaid API в Airflow и dbt модели
• накатать документацию по Subscription (это единственный прощальный проект, про который я писал, но решил сдаться)
• изучить новую фичу Claude Code Agent Teams и запустить тест по созданию с нуля Azure Data Warehouse с Azure SQL Server, Azure CosmosDB, Azure Postgres, Azure Data Factory, Azure DevOps repos и pipelines. Я дал доступ к своему Azure аккаунту и поставил задачу создать всё самостоятельно — ещё создаёт. То есть если подождать немного, то уже не нужны всякие сложные GasTown, Multi Claude и т.п. У Cursor тоже есть Parallel Agents. Но у меня пока нет таких задач, где нужно вместе так рабоать, лучше просто режим YOLO и погнали 😡
Это что пришло в голову с ходу.
Очевидно одно: с такими возможностями можно реализовать любую идею очень быстро. Не знаю как у вас, но у меня 80-90% работы идёт через AI. Со вчерашнего дня использую уже Opus 4.6. Конечно, где-то бывают затыки, но вместе с AI всё решаемо. Для всех Surfalytics members AI IDE — must have. Без AI, я бы тоже самое делал бы 5 недель.
Telegram
Принес вам немножко инсайтов. В одной большой компании, которая управляет большим капиталом (wealth management) внедряют Databricks, чтобы
1) модернизировать legacy
2) дать возможность партнерам использовать централизованную платформу
3) добавить ML и GenAI возможности
В компании прям все очень грустно с точки зрения мотивации, люди просиживают штаны. Соотвественно, компания используют подрядчика. Подрядчик, пользуется этой слабостью компании и диктует свои условия. VP data&ai решил меня записать в advisory и показал мне price в час консультантов:
Accountable Executive - $361
Engagement Lead - $309
Data Architect - $309
Data Engineer - $242
Senior Data & AI Engineer - $278
DevOps Architect - $309
Для сравнения в Канаде, если вы хотите работать как контактор, вы можете максимально получать 95-100$, даже если работать на прямую на компанию. А если на фирму прослойку, то это уже 55-65$. Вот такой вот беспредел.
Особенно интересно смотреть на full time загрузку Engagement Lead, кто по факту просто выполняет роль PM и каждый день проводит standup. И самое печальное в этой истории, что сотрудники самой компании не использую возможность перенять опыт у дорогих консультантов и не хотят развиваться. И так как VP сидит высоко, а инженерам все-равно, получается, что VP покупает “кота в мешке” у консалтинговой компании, которая обещает AI звездолет (по методичке), и каждый новый проект начинается с чистого листа, даже если это продолжение прошлого проекта.
Так как ознакомился со скоупом, я предложил кардинально другое решение, которое лучше и проще и заодно должно быть на 50% дешевле. Можно было и самим все сделать, но “таков путь” большого enterprise.
1) модернизировать legacy
2) дать возможность партнерам использовать централизованную платформу
3) добавить ML и GenAI возможности
В компании прям все очень грустно с точки зрения мотивации, люди просиживают штаны. Соотвественно, компания используют подрядчика. Подрядчик, пользуется этой слабостью компании и диктует свои условия. VP data&ai решил меня записать в advisory и показал мне price в час консультантов:
Accountable Executive - $361
Engagement Lead - $309
Data Architect - $309
Data Engineer - $242
Senior Data & AI Engineer - $278
DevOps Architect - $309
Для сравнения в Канаде, если вы хотите работать как контактор, вы можете максимально получать 95-100$, даже если работать на прямую на компанию. А если на фирму прослойку, то это уже 55-65$. Вот такой вот беспредел.
Особенно интересно смотреть на full time загрузку Engagement Lead, кто по факту просто выполняет роль PM и каждый день проводит standup. И самое печальное в этой истории, что сотрудники самой компании не использую возможность перенять опыт у дорогих консультантов и не хотят развиваться. И так как VP сидит высоко, а инженерам все-равно, получается, что VP покупает “кота в мешке” у консалтинговой компании, которая обещает AI звездолет (по методичке), и каждый новый проект начинается с чистого листа, даже если это продолжение прошлого проекта.
Так как ознакомился со скоупом, я предложил кардинально другое решение, которое лучше и проще и заодно должно быть на 50% дешевле. Можно было и самим все сделать, но “таков путь” большого enterprise.
Telegram
После косяков с clawd/moltbot я не решился ставить его. Но народ прям доволен, кто пользуется? Какие кейсы у вас?
Telegram
Хороший update от эксперта в AI https://x.com/karpathy/status/2015883857489522876?s=46
Это заметки о том, как AI-ассистенты (особенно Claude) радикально изменили процесс программирования за последние месяцы.
Основные идеи:
Революция в рабочем процессе
• Автор перешёл от 80% ручного кодирования к 80% работы через AI-агентов за несколько недель (ноябрь-декабрь 2025)
• Теперь он буквально "программирует на английском языке", описывая словами, что должен делать код
• Это самое большое изменение в его практике программирования за 20 лет
Проблемы и ограничения
• Модели всё ещё делают ошибки — не синтаксические, а концептуальные (как "торопливый джуниор")
• Они делают предположения без проверки, не просят уточнений, не указывают на противоречия
• Усложняют код без необходимости, раздувают абстракции, не убирают мёртвый код
• Нужно следить за их работой в IDE
Новые возможности
• Выносливость: агенты никогда не устают и не деморализуются, могут работать над проблемой 30+ минут
• Расширение возможностей: можно делать вещи, которые раньше "не стоили усилий", или работать с незнакомым кодом
• Веселье: программирование стало интереснее, осталась только творческая часть
Последствия
• Атрофия навыков ручного кодирования
• Грядущий "slopacolypse" (лавина низкокачественного AI-контента) в 2026 году
• Вопросы о будущем: что станет с "10x инженерами"? Будут ли генералисты превосходить специалистов?
Вывод: В декабре 2025 AI-агенты (Claude, Codex) пересекли порог когерентности, вызвав фазовый переход в софтверной инженерии. 2026 будет годом адаптации индустрии к этой новой реальности.
Мне особенно нравится секция “последствия”.
Это заметки о том, как AI-ассистенты (особенно Claude) радикально изменили процесс программирования за последние месяцы.
Основные идеи:
Революция в рабочем процессе
• Автор перешёл от 80% ручного кодирования к 80% работы через AI-агентов за несколько недель (ноябрь-декабрь 2025)
• Теперь он буквально "программирует на английском языке", описывая словами, что должен делать код
• Это самое большое изменение в его практике программирования за 20 лет
Проблемы и ограничения
• Модели всё ещё делают ошибки — не синтаксические, а концептуальные (как "торопливый джуниор")
• Они делают предположения без проверки, не просят уточнений, не указывают на противоречия
• Усложняют код без необходимости, раздувают абстракции, не убирают мёртвый код
• Нужно следить за их работой в IDE
Новые возможности
• Выносливость: агенты никогда не устают и не деморализуются, могут работать над проблемой 30+ минут
• Расширение возможностей: можно делать вещи, которые раньше "не стоили усилий", или работать с незнакомым кодом
• Веселье: программирование стало интереснее, осталась только творческая часть
Последствия
• Атрофия навыков ручного кодирования
• Грядущий "slopacolypse" (лавина низкокачественного AI-контента) в 2026 году
• Вопросы о будущем: что станет с "10x инженерами"? Будут ли генералисты превосходить специалистов?
Вывод: В декабре 2025 AI-агенты (Claude, Codex) пересекли порог когерентности, вызвав фазовый переход в софтверной инженерии. 2026 будет годом адаптации индустрии к этой новой реальности.
Мне особенно нравится секция “последствия”.
Telegram
ETL в облаке: от хаоса к управляемым процессам
Разрозненные источники данных, ручные скрипты и постоянные сбои в ETL-процессах создают хаос. Это приводит к задержкам в аналитике, ошибкам в отчетах и потере времени на поддержку инфраструктуры вместо создания ценности для бизнеса.
На вебинаре 12 февраля эксперт Cloud.ru расскажет, как создать надежную и масштабируемую ETL-платформу в облаке за считанные часы.
В программе:
😶🌫️как интегрировать данные из различных источников (базы данных, S3, API) в единую экосистему с помощью Evolution Managed Spark и Managed Airflow;
😶🌫️как централизовать управление метаданными и схемами с помощью Evolution Managed Metastore для согласованности и качества данных;
😶🌫️как настроить SQL-запросы к разнородным источникам через Evolution Managed Trino без переноса данных;
😶🌫️как оценить экономию времени и ресурсов при переходе с self-hosted решений на managed-сервисы.
В практической части получится настроить ETL-пайплайн от извлечения данных до формирования витрины и выполнить трансформации.
Зарегистрироваться
Разрозненные источники данных, ручные скрипты и постоянные сбои в ETL-процессах создают хаос. Это приводит к задержкам в аналитике, ошибкам в отчетах и потере времени на поддержку инфраструктуры вместо создания ценности для бизнеса.
На вебинаре 12 февраля эксперт Cloud.ru расскажет, как создать надежную и масштабируемую ETL-платформу в облаке за считанные часы.
В программе:
😶🌫️как интегрировать данные из различных источников (базы данных, S3, API) в единую экосистему с помощью Evolution Managed Spark и Managed Airflow;
😶🌫️как централизовать управление метаданными и схемами с помощью Evolution Managed Metastore для согласованности и качества данных;
😶🌫️как настроить SQL-запросы к разнородным источникам через Evolution Managed Trino без переноса данных;
😶🌫️как оценить экономию времени и ресурсов при переходе с self-hosted решений на managed-сервисы.
В практической части получится настроить ETL-пайплайн от извлечения данных до формирования витрины и выполнить трансформации.
Зарегистрироваться

Telegram
Больше всего в ру сегменте люблю читать про 🐺- https://habr.com/ru/companies/it_sense/articles/916176/
Одни кайфуют и сыпят баблом, другие им завидуют и размышляют на тему как это плохо, как страдает вся индустрия.
Русский АйТи как ковчег, где на всех места не хватит все ссорятся между собой.
А тем временем AI наступает на пятки, компании могут сокращать, а зарплаты не растут.
Какие там еще движухи интересные? Вот слышал про млн индусов, они как в ИТ или куда планируют?
Одни кайфуют и сыпят баблом, другие им завидуют и размышляют на тему как это плохо, как страдает вся индустрия.
Русский АйТи как ковчег, где на всех места не хватит все ссорятся между собой.
А тем временем AI наступает на пятки, компании могут сокращать, а зарплаты не растут.
Какие там еще движухи интересные? Вот слышал про млн индусов, они как в ИТ или куда планируют?
Telegram
Строчка из свежего job offer
Увольнения: В связи с экономическими или иными деловыми условиями Компания может временно отстранить вас от работы. Любое такое временное отстранение, при условии что оно соответствует требованиям ESA, не будет являться прекращением вашей трудовой деятельности или конструктивным увольнением.
Ну то есть если вы выходите на новую работу, у вас нет абсолютно никаких гарантий. Раньше я такой пункт не видел, а теперь это обычная практика.
🙅♂️
Увольнения: В связи с экономическими или иными деловыми условиями Компания может временно отстранить вас от работы. Любое такое временное отстранение, при условии что оно соответствует требованиям ESA, не будет являться прекращением вашей трудовой деятельности или конструктивным увольнением.
Ну то есть если вы выходите на новую работу, у вас нет абсолютно никаких гарантий. Раньше я такой пункт не видел, а теперь это обычная практика.
🙅♂️

Telegram
Планируем поезду в LA в середине марта, чтобы взять 911 и на нем покататься по побережью до SF.
Можно как обычно на сидр где-нибудь встретиться или еще чего сделать🥇
Можно как обычно на сидр где-нибудь встретиться или еще чего сделать🥇
Telegram
Life hack для менеджера и тимлида — Монополия на знание
• Ставите себе Claude Code / Cursor.
• Подключаете все возможные MCP (Confluence, Git, базы данных и т. д.).
• Настраиваете CLI для ваших сервисов (CI/CD, Infra, Monitoring и т. д.).
• Подключаетесь к Jira, чтобы всё мониторилось за вас.
• Записи всех встреч скармливаете в AI и получаете готовый backlog и Action Items.
Добавляете еще несколько полезных интеграций по вкусу.
Но самое главное: вы официально запрещаете использовать AI на работе под страхом увольнения. Ведь это «небезопасно» и «не комплаенс».
Таким образом, вы становитесь «Брюсом Тимлидом Всемогущим», реализуя исторические модели доминирования:
• «Вассал собирал оброк с крестьян»
• «Феодал взимал дань с зависимых крестьян»
• «Помещик собирал подати с крепостных»
• «Землевладелец получал ренту от крестьян»
Но пока часто получается наоборот: один инженер втихую делает всё сам, пока менеджеры пропадают на встречах, а команда погрязла в рутине и не находит времени на самосовершенствование.
• Ставите себе Claude Code / Cursor.
• Подключаете все возможные MCP (Confluence, Git, базы данных и т. д.).
• Настраиваете CLI для ваших сервисов (CI/CD, Infra, Monitoring и т. д.).
• Подключаетесь к Jira, чтобы всё мониторилось за вас.
• Записи всех встреч скармливаете в AI и получаете готовый backlog и Action Items.
Добавляете еще несколько полезных интеграций по вкусу.
Но самое главное: вы официально запрещаете использовать AI на работе под страхом увольнения. Ведь это «небезопасно» и «не комплаенс».
Таким образом, вы становитесь «Брюсом Тимлидом Всемогущим», реализуя исторические модели доминирования:
• «Вассал собирал оброк с крестьян»
• «Феодал взимал дань с зависимых крестьян»
• «Помещик собирал подати с крепостных»
• «Землевладелец получал ренту от крестьян»
Но пока часто получается наоборот: один инженер втихую делает всё сам, пока менеджеры пропадают на встречах, а команда погрязла в рутине и не находит времени на самосовершенствование.

Telegram
Live stream finished (56 minutes)
Telegram
Чтобы увидеть пост, перейдите в Telegram
Telegram
Недавно столкнулся с задачкой, когде мне понадобился git worktree и tmux для агента. Первый шаг к AI конвейеру.
tmux — программа для терминала, которая позволяет:
• Разделить один терминал на несколько окон — работай в нескольких местах одновременно
• Не терять работу при отключении — закрыл терминал или оборвалось SSH-соединение? Всё продолжает работать, можно вернуться позже
• Запускать долгие процессы на сервере — отключился, а программа работает
Простой пример
Подключился к серверу → запустил tmux → запустил долгую задачу → отключился от сервера → задача продолжает работать → подключился обратно → всё на месте
Коротко: это как вкладки в браузере, но для терминала, и они не закрываются, даже если ты вышел.
Git worktree — это возможность Git создать несколько рабочих копий одного репозитория с разными бранчами одновременно.
Зачем нужен:
Обычно в одной папке репозитория можно работать только с одним бранчем. Git worktree позволяет работать с несколькими бранчами параллельно без переключения.
Как работает:
```
# Основной репозиторий в ~/project (бранч main)
cd ~/project
# Создать worktree для другого бранча
git worktree add ../project-feature-1 feature-1
git worktree add ../project-feature-2 feature-2
```
Теперь у тебя:
• ~/project — бранч main
• ~/project-feature-1 — бранч feature-1
• ~/project-feature-2 — бранч feature-2
Все три папки связаны с одним репозиторием (один .git), но работают с разными бранчами.
Преимущества:
• Не нужно переключать бранчи и коммитить незаконченную работу
• Можно открыть разные бранчи в разных редакторах (Claude Code в одном, Cursor в другом)
• Экономит время — не нужно клонировать репозиторий несколько раз
Коротко: один репозиторий, несколько папок, разные бранчи одновременно.
Так как я теперь работаю сразу в Claude Code и Cursor на своём Mac, я не могу работать в одном Git Branch. Точнее, я начал это делать, и потом у меня 2 задачи склеились в одну внутри одной ветки, причём частично. (На Windows машинах я использую VSCode + KiloCode, так как нет админского доступа)
Таким образом, сразу возникает потребность в разделении веток на одной машине. Git worktree решает эту проблему, а tmux помогает удобно управлять несколькими терминальными сессиями для работы с разными worktree одновременно.
Дальше нужно попробовать добавить OpenSpec, чтобы поставить задачу и разбить её на подзадачи, чтобы запустить несколько агентов параллельно.
Именно в AI у меня три направления:
1. Разработка с AI — это самое простое, просто нужно следить за обновлениями и примерами и пробовать на своих задачах.
2. Бизнес-кейсы для DE — тут в теории понятно, а вот техническая реализация требует времени. Сейчас очень популярно делать RAG, chat bot, Agent workflow или использовать GenAI для автоматизации. Часть кейсов хочу внедрить в Surfalytics, для этого мигрирую на Netlify + Supabase.
3. Личные агенты и ассистенты — на рынке много продуктов, которые могут делать простые задачи. Например, на базе моих календарей и задач в Notion, Jira, Asana сделать примерное расписание дня и забукать слоты в календаре. Или совсем простой кейс — каждый раз, когда делаю PR или работаю над задачей, заводить новый тикет через MCP и отслеживать все тикеты и обновлять статусы.
tmux — программа для терминала, которая позволяет:
• Разделить один терминал на несколько окон — работай в нескольких местах одновременно
• Не терять работу при отключении — закрыл терминал или оборвалось SSH-соединение? Всё продолжает работать, можно вернуться позже
• Запускать долгие процессы на сервере — отключился, а программа работает
Простой пример
Подключился к серверу → запустил tmux → запустил долгую задачу → отключился от сервера → задача продолжает работать → подключился обратно → всё на месте
Коротко: это как вкладки в браузере, но для терминала, и они не закрываются, даже если ты вышел.
Git worktree — это возможность Git создать несколько рабочих копий одного репозитория с разными бранчами одновременно.
Зачем нужен:
Обычно в одной папке репозитория можно работать только с одним бранчем. Git worktree позволяет работать с несколькими бранчами параллельно без переключения.
Как работает:
```
# Основной репозиторий в ~/project (бранч main)
cd ~/project
# Создать worktree для другого бранча
git worktree add ../project-feature-1 feature-1
git worktree add ../project-feature-2 feature-2
```
Теперь у тебя:
• ~/project — бранч main
• ~/project-feature-1 — бранч feature-1
• ~/project-feature-2 — бранч feature-2
Все три папки связаны с одним репозиторием (один .git), но работают с разными бранчами.
Преимущества:
• Не нужно переключать бранчи и коммитить незаконченную работу
• Можно открыть разные бранчи в разных редакторах (Claude Code в одном, Cursor в другом)
• Экономит время — не нужно клонировать репозиторий несколько раз
Коротко: один репозиторий, несколько папок, разные бранчи одновременно.
Так как я теперь работаю сразу в Claude Code и Cursor на своём Mac, я не могу работать в одном Git Branch. Точнее, я начал это делать, и потом у меня 2 задачи склеились в одну внутри одной ветки, причём частично. (На Windows машинах я использую VSCode + KiloCode, так как нет админского доступа)
Таким образом, сразу возникает потребность в разделении веток на одной машине. Git worktree решает эту проблему, а tmux помогает удобно управлять несколькими терминальными сессиями для работы с разными worktree одновременно.
Дальше нужно попробовать добавить OpenSpec, чтобы поставить задачу и разбить её на подзадачи, чтобы запустить несколько агентов параллельно.
Именно в AI у меня три направления:
1. Разработка с AI — это самое простое, просто нужно следить за обновлениями и примерами и пробовать на своих задачах.
2. Бизнес-кейсы для DE — тут в теории понятно, а вот техническая реализация требует времени. Сейчас очень популярно делать RAG, chat bot, Agent workflow или использовать GenAI для автоматизации. Часть кейсов хочу внедрить в Surfalytics, для этого мигрирую на Netlify + Supabase.
3. Личные агенты и ассистенты — на рынке много продуктов, которые могут делать простые задачи. Например, на базе моих календарей и задач в Notion, Jira, Asana сделать примерное расписание дня и забукать слоты в календаре. Или совсем простой кейс — каждый раз, когда делаю PR или работаю над задачей, заводить новый тикет через MCP и отслеживать все тикеты и обновлять статусы.
Telegram
А Antropic есть станица с курсами. Я сам не проходил, но дал задание сыну (13 лет)
• AI Fluency for Students
• Claude 101
• Claude Code in Action
Раньше у него был VSCode + KiloCode, и он создавал простые игры. Я ему настроил Claude Code в CLI, и он сказал ему намного удобней работать в командной строке, чем в VSCode. Для меня это было неожиданно. Мне вот неудобно в CLI работать, я же не вижу файлы, которые меняется. А для него эти файлы были шумом, он сфокусирован на конечном продукте, и всякие там js, css файлы это лишняя абстракция, которую он еще не знает. Я его похвалил, что он делает крутые успехи, ведь даже в этом канале мало кто использует Claude Code😝
Конечно возникает вопрос - как же так, отдать AI весь процесс создания, а самому только смотреть на input/output. Возможно так и будет скоро и новое поколение явно будет использовать AI по другому. Я ему помог нарисовать диаграмму карандашом, что у нас происходит и как можно через API генерить картинки при загрузке страницы. Дальше я хочу, чтобы он загрузил эту игру (продукт) в Netlify (хостинг) и добавь настоящий домен. Таким образом будет пример end-to-end продукта. Я в 8 классе играл в Sims, Fallout 2 и Commandos, а тут такое раздолье. Так же каждый вечер мы слушаем summary книг про компании и бизнес и мой главный point для детей, что важна дисциплина, фокус и consistency.
На подходе у нас Mini Reachy - open source робот (300 деталей), который умеет разговорить и видеть, обязательно напишу про него, когда соберем. Еще детям очень понравились проекты от Mark Robert - Crunch Labs.
Что касается меня, то я решил параллельно работать на Cursor и на Claude Code (CLI), чтобы не отставать от трендов.
PS Вот прям сейчас AI сэкономил мне 150$. На кухне выбило пробки и перестал работать фильтр и половину розеток. В щитке я включал/выключал все - не помогло. Уже думали завтра вызвать мастера. Я сфоткал свои розетки и щиток, рассказал симптомы и получил решение - на одной из розеток на кухне есть circuit breaker, я его нашел и нажал, все заработало! Электрики скоро без работы останутся! 😆
#дети #ai
• AI Fluency for Students
• Claude 101
• Claude Code in Action
Раньше у него был VSCode + KiloCode, и он создавал простые игры. Я ему настроил Claude Code в CLI, и он сказал ему намного удобней работать в командной строке, чем в VSCode. Для меня это было неожиданно. Мне вот неудобно в CLI работать, я же не вижу файлы, которые меняется. А для него эти файлы были шумом, он сфокусирован на конечном продукте, и всякие там js, css файлы это лишняя абстракция, которую он еще не знает. Я его похвалил, что он делает крутые успехи, ведь даже в этом канале мало кто использует Claude Code😝
Конечно возникает вопрос - как же так, отдать AI весь процесс создания, а самому только смотреть на input/output. Возможно так и будет скоро и новое поколение явно будет использовать AI по другому. Я ему помог нарисовать диаграмму карандашом, что у нас происходит и как можно через API генерить картинки при загрузке страницы. Дальше я хочу, чтобы он загрузил эту игру (продукт) в Netlify (хостинг) и добавь настоящий домен. Таким образом будет пример end-to-end продукта. Я в 8 классе играл в Sims, Fallout 2 и Commandos, а тут такое раздолье. Так же каждый вечер мы слушаем summary книг про компании и бизнес и мой главный point для детей, что важна дисциплина, фокус и consistency.
На подходе у нас Mini Reachy - open source робот (300 деталей), который умеет разговорить и видеть, обязательно напишу про него, когда соберем. Еще детям очень понравились проекты от Mark Robert - Crunch Labs.
Что касается меня, то я решил параллельно работать на Cursor и на Claude Code (CLI), чтобы не отставать от трендов.
PS Вот прям сейчас AI сэкономил мне 150$. На кухне выбило пробки и перестал работать фильтр и половину розеток. В щитке я включал/выключал все - не помогло. Уже думали завтра вызвать мастера. Я сфоткал свои розетки и щиток, рассказал симптомы и получил решение - на одной из розеток на кухне есть circuit breaker, я его нашел и нажал, все заработало! Электрики скоро без работы останутся! 😆
#дети #ai
Telegram
Там много классных AI штук появляется на рынке, что и не успеваешь за всем уследить, в Discord Surfalytics у нас даже есть специальные канал dev-boost-with-ai, где я собираю самое важное, что может повлиять на нашу работу.
Буквально на днях увидел про Clawbot. Судя по отзывам топ инструмент, который служит персональным ассистентом и живет на локальной машине (бесплатный и открытый).
Я хотел его попробовать для автоматизации создания и мониторинга задач в Jira, Notion, Asana. У меня всегда с этим проблема, я не создаю и не обновляю задачки.
А сегодня ребята скинули пост - From Clawdbot to Moltbot: How a C&D, Crypto Scammers, and 10 Seconds of Chaos Took Down the Internet's Hottest AI Project
Эта статья рассказывает о драматической истории проекта Clawdbot (теперь Moltbot) — самостоятельно размещаемого AI-ассистента, который за 72 часа пережил настоящий хаос.
Основные моменты:
Взлёт проекта
• Clawdbot набрал 60,800+ звёзд на GitHub за рекордно короткое время
• Это был AI-ассистент с "руками" — не просто чат, а инструмент, который реально выполнял действия (доступ к файлам, браузеру, командной строке)
• Поддерживал 50+ интеграций и работал через WhatsApp, Telegram, Slack, iMessage и другие платформы
Принудительный ребрендинг
• Anthropic (создатели Claude) потребовали сменить название из-за схожести "Clawd" с "Claude"
• Проект переименовали в Moltbot (от слова "molt" — линька у омаров, символ роста)
10 секунд хаоса
• При переименовании аккаунтов GitHub и X/Twitter основатель допустил ошибку
• Криптоскамеры перехватили старые аккаунты за ~10 секунд и начали рассылать мошеннические объявления
• Появились фейковые токены $CLAWD на Solana с капитализацией до $16 млн, которые затем обрушились
Проблемы безопасности
• Исследователи обнаружили сотни публично доступных экземпляров Moltbot с открытыми учётными данными
• Через Shodan можно было найти API-ключи, токены ботов, историю переписок и возможность удалённого выполнения кода
• Демонстрация показала, как за 5 минут можно перехватить письма пользователя через prompt injection
Вопросы к Anthropic
• Многие пользователи Moltbot использовали Claude как основную модель, фактически продвигая продукт Anthropic
• Сообщество недоумевает: зачем компания преследует проект, который увеличивал продажи их подписок?
Выводы статьи:
История показывает хрупкость экосистемы AI и open-source проектов — один юридический запрос может запустить цепную реакцию из взломов, скамов и хаоса. Проект технически остаётся сильным, но репутационный ущерб огромен.
Будьте аккуратны с новыми инструментами.
Буквально на днях увидел про Clawbot. Судя по отзывам топ инструмент, который служит персональным ассистентом и живет на локальной машине (бесплатный и открытый).
Я хотел его попробовать для автоматизации создания и мониторинга задач в Jira, Notion, Asana. У меня всегда с этим проблема, я не создаю и не обновляю задачки.
А сегодня ребята скинули пост - From Clawdbot to Moltbot: How a C&D, Crypto Scammers, and 10 Seconds of Chaos Took Down the Internet's Hottest AI Project
Эта статья рассказывает о драматической истории проекта Clawdbot (теперь Moltbot) — самостоятельно размещаемого AI-ассистента, который за 72 часа пережил настоящий хаос.
Основные моменты:
Взлёт проекта
• Clawdbot набрал 60,800+ звёзд на GitHub за рекордно короткое время
• Это был AI-ассистент с "руками" — не просто чат, а инструмент, который реально выполнял действия (доступ к файлам, браузеру, командной строке)
• Поддерживал 50+ интеграций и работал через WhatsApp, Telegram, Slack, iMessage и другие платформы
Принудительный ребрендинг
• Anthropic (создатели Claude) потребовали сменить название из-за схожести "Clawd" с "Claude"
• Проект переименовали в Moltbot (от слова "molt" — линька у омаров, символ роста)
10 секунд хаоса
• При переименовании аккаунтов GitHub и X/Twitter основатель допустил ошибку
• Криптоскамеры перехватили старые аккаунты за ~10 секунд и начали рассылать мошеннические объявления
• Появились фейковые токены $CLAWD на Solana с капитализацией до $16 млн, которые затем обрушились
Проблемы безопасности
• Исследователи обнаружили сотни публично доступных экземпляров Moltbot с открытыми учётными данными
• Через Shodan можно было найти API-ключи, токены ботов, историю переписок и возможность удалённого выполнения кода
• Демонстрация показала, как за 5 минут можно перехватить письма пользователя через prompt injection
Вопросы к Anthropic
• Многие пользователи Moltbot использовали Claude как основную модель, фактически продвигая продукт Anthropic
• Сообщество недоумевает: зачем компания преследует проект, который увеличивал продажи их подписок?
Выводы статьи:
История показывает хрупкость экосистемы AI и open-source проектов — один юридический запрос может запустить цепную реакцию из взломов, скамов и хаоса. Проект технически остаётся сильным, но репутационный ущерб огромен.
Будьте аккуратны с новыми инструментами.
Telegram
Live stream finished (1 hour)
Telegram
Live stream started
Telegram
🎓Старый добрый формат вебинаров 🎓
27 января в 20:00 по мск
Здесь в канале трансляция...
🖥 Тема: Единое пространство аналитики, или просто Тенгри.
⭐ Спикер - Голов Николай, последние годы строил аналитические платформы на таких системах как Snowflake и Databricks, о которых часто говорит Дмитрий.
🧩Собрал стартап, вместе с командой запилили аналог, о чем и расскажет нам.
На вебинаре мы попробуем разобраться, почему десятки тысяч компаний выбрали Snowflake, а те, кто хочет локальное развертывание, смогут выбрать Tengri Data Platform ( который доступнен как на своем железе так и в облаках, объединяющий хранение, трансформацию, визуализацию данных, SQL и Python, и все это для десятков и сотен TB).
🧠 Николай неоднократно выступал у нас, легендарные материалы про Data Vault Modeling (Можете найти на ютуб канале)
#Вебинар #datalearn
27 января в 20:00 по мск
Здесь в канале трансляция...
🖥 Тема: Единое пространство аналитики, или просто Тенгри.
⭐ Спикер - Голов Николай, последние годы строил аналитические платформы на таких системах как Snowflake и Databricks, о которых часто говорит Дмитрий.
🧩Собрал стартап, вместе с командой запилили аналог, о чем и расскажет нам.
На вебинаре мы попробуем разобраться, почему десятки тысяч компаний выбрали Snowflake, а те, кто хочет локальное развертывание, смогут выбрать Tengri Data Platform ( который доступнен как на своем железе так и в облаках, объединяющий хранение, трансформацию, визуализацию данных, SQL и Python, и все это для десятков и сотен TB).
🧠 Николай неоднократно выступал у нас, легендарные материалы про Data Vault Modeling (Можете найти на ютуб канале)
#Вебинар #datalearn
Telegram
Чтобы увидеть пост, перейдите в Telegram
Telegram
Данная страница сгенерирована автоматически. Владельцам канала доступ предоставляется по запросу
